
Why Is My AI Model’s Performance Degrading? How to Solve Model Drift
AI models, especially Large Language Models (LLMs), don’t degrade like perishable goods. But over time, you’ll …

Healthcare data is as vast as it is complex, encompassing millions of medical records, clinical notes, diagnostic reports, and administrative documents generated each day. AI-native Intelligent Document Processing is crucial in handling this data, given its massive volume and diverse formats—ranging from structured Electronic Health Records (EHRs) to unstructured handwritten notes or scanned documents.
The stakes in healthcare data management are exceptionally high. Errors in processing or misclassifications can lead to delayed care, incorrect billing, or compliance violations. Moreover, the sensitive nature of this data demands unwavering adherence to privacy regulations like HIPAA, adding another layer of complexity. Traditional methods of data indexing and retrieval, reliant on manual intervention or template-based systems, often fall short of meeting these challenges at scale.
At Dexit, we’ve harnessed AI-native Intelligent Document Processing to simplify and supercharge the indexing of medical records. By using cutting-edge machine learning, we perform document classification and entity extraction, our platform doesn't just automate—it redefines how medical records are processed. No barcodes. No rigid templates. Just high-speed, high-accuracy solutions built to handle complex, real-world healthcare documentation. Going beyond advanced LLMs, Dexit is trained on the specific demands and data of the healthcare industry, delivering precision and performance where it matters most.
This blog unpacks the tech behind Dexit’s Intelligent Document Processing: the experiments, breakthroughs, and engineering finesse that make it a game-changer for health tech pros.
Let’s get into the details—how it works, where it excels, and what’s next.
Contents
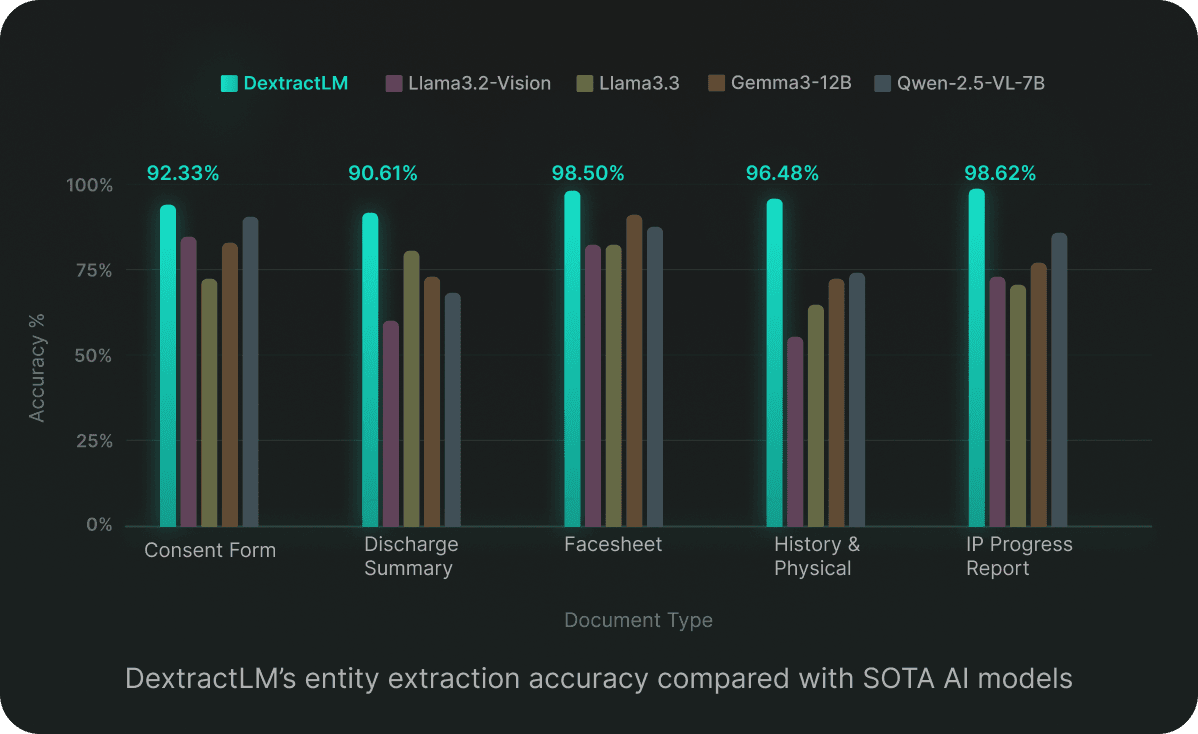
Dexit revolutionizes healthcare document management with Intelligent Document Processing to classify files, extract key entities, and enable seamless auto-indexing. This capability allows organizations to handle vast and complex document repositories efficiently, eliminating reliance on traditional identifiers like templates or barcodes. Instead, Dexit leverages visual and spatial context for unmatched accuracy in extracting details such as patient names and addresses.
However, achieving this level of precision was no straightforward feat. The Dexit team explored multiple avenues for document classification and entity extraction before arriving at the optimal solution through AI-native Intelligent Document Processing.
Early experiments focused on image similarity metrics, utilizing methods like Structural Similarity Index Measure (SSIM) and Mean Squared Error (MSE) to group visually similar pages. While this achieved modest success, its inability to incorporate textual content resulted in misclassifications when documents with similar layouts varied in type.
Next, the team developed a fusion strategy, combining visual and textual analysis through models like CNN and ResNet alongside ClinicalBERT for text classification. Although accuracy improved, the inability to account for spatial relationships between text elements limited its effectiveness, particularly for complex layouts like forms and invoices.
The breakthrough came with the adoption of a State-of-the-Art (SOTA) image classification model. This approach integrates both visual and spatial information, enabling highly accurate classification even for structured documents. Trained on a dataset of 30,000 images spanning 100 document types, this solution achieved 97% accuracy overall, with some room for improvement in documents with high variation.
The journey of entity extraction was equally rigorous. Initial methods included tools like DocQuery, which struggled due to lack of support and adaptability, and InternVL 2.0, which excelled at question answering but faltered in token-level entity extraction. Similarly, BERT required extensive preprocessing and lacked document structural awareness, making it inefficient for Dexit’s needs.
The final solution combines a fine-tuned model with an OCR and Large Language Model (LLM) workflow, tailored to specific document requirements:
Dexit’s final design delivers a powerful blend of classification, extraction, and indexing capabilities, allowing users to search and retrieve documents based on content rather than tags. Whether handling invoices, medical reports, or forms, Dexit streamlines workflows, reduces errors, and saves time.
Here’s a quick look at the Dexit way of handling document classification and entity extraction:

For a deeper look at the technical decisions and key takeaways, explore how Dexit approaches AI-powered document extraction and classification.
Dexit’s approach to achieving high accuracy in entity extraction extends beyond traditional text-based models by integrating textual, visual, and spatial information. This enables the model to make nuanced and accurate predictions, particularly for structured documents. Here’s a breakdown of the key strategies:
For both document type classification and entity extraction, thorough Exploratory Data Analysis (EDA) is performed to ensure that the models are trained with clean, high-quality data. This process maximizes model performance by identifying key patterns and preparing data for optimal model input. Here's a breakdown of the steps involved:
Dexit’s AI integrates human feedback into its document processing models to continuously refine and improve accuracy. This feedback loop is managed through a robust MLOps pipeline, which automatically triggers model retraining when certain conditions are met. Here's how the system works:
Dexit's feedback-driven approach ensures consistent accuracy, efficiency, and adaptability in its document processing models, making sure the system improves over time.
The MLOps pipeline at Dexit relies on several essential technologies to streamline and enhance machine learning workflows. ClearML manages the entire process, including data versioning, task distribution across Kubernetes clusters, and experiment tracking. GitHub serves as the central repository for source code, training scripts, data preparation workflows, and configuration files, ensuring version control and collaboration. Hugging Face oversees model registry, version control, and deployment of retrained models, while SkyPilot automates the deployment and management of ClearML agents on cloud clusters, triggered by GitHub Actions. By integrating these tools, Dexit has built a scalable, automated system that learns from human feedback and continuously enhances its document processing capabilities.
At Dexit, our commitment to data privacy is a core principle that drives everything we do. Unlike many AI solutions that rely on third-party cloud infrastructures, we operate entirely on-premise, giving our clients complete control over their data. This on-premise approach ensures that sensitive information never leaves the client's environment, safeguarding against data breaches or misuse. Furthermore, we tailor our models specifically to each client's data, fine-tuning them to meet unique needs and challenges. By avoiding external vendors, we eliminate the risks associated with sharing data, allowing our clients to trust that their privacy is always a top priority while still benefiting from advanced AI-powered solutions.
Dexit is constantly enhancing its AI-native Intelligent Document Processing capabilities through a combination of advanced AI techniques, robust infrastructure, and a commitment to incorporating human feedback. Here are the key areas where Dexit is set to improve:
By leveraging AI-native Intelligent Document Processing, Dexit ensures that medical records are indexed, classified, and extracted with precision, setting new benchmarks for efficiency and accuracy in healthcare document management.
CONTRIBUTORS BEHIND THE BUILD
Join over 3,200 subscribers and keep up-to-date with the latest innovations & best practices in Healthcare IT.
AI models, especially Large Language Models (LLMs), don’t degrade like perishable goods. But over time, you’ll …

Dexit stands out with its ability to classify documents, extract key entities, and enable seamless …

So, you've deployed your shiny new ML model. It's acing predictions, and life is good. But how do you …