
How to Architect a Self-improving ML System with Automated Model Retraining
So, you've deployed your shiny new ML model. It's acing predictions, and life is good. But how do you …

Dexit stands out with its ability to classify documents, extract key entities, and enable seamless auto-indexing — redefining efficiency in automated document processing and management.
At the heart of Dexit’s performance is a cutting-edge approach that emulates human comprehension of documents. By leveraging visual and spatial context, Dexit accurately categorizes files — from forms and invoices to complex medical reports. What sets Dexit apart is its independence from traditional identifiers like document-type templates or patient-identifying barcodes. Instead, its advanced entity extraction capabilities identify and retrieve critical details, such as patient names, dates, and addresses, with unmatched precision.
This synergy of intelligent classification, robust entity extraction, and fast, automated indexing makes Dexit an indispensable tool for organizations managing vast and complex document repositories. Users can locate relevant files effortlessly, based on content rather than predefined tags, saving time and reducing errors.
However, arriving at this final solution was no straightforward journey. Our team explored, tested, and refined multiple approaches for AI document extraction and classification. Here’s a closer look at the paths we took, the challenges we overcame, and the insights that shaped Dexit’s ultimate design.
What We Cover:
To tackle document classification, we initially experimented with image similarity metrics, relying on visual cues to determine document types. The approach involved sliding through pages of documents, and comparing the current page to the previous one to identify visual differences that could signal a page break. Pages with high visual similarity were grouped together as part of the same document.
We tested several metrics:
While testing SSIM yielded an accuracy of 71% for detecting page breaks at a specific threshold, the overall precision of these methods remained around 70%. A major limitation here was their inability to account for textual content, leading to misclassifications when documents of different types had visually similar layouts.
To overcome these limitations, we experimented with a fusion strategy, combining image classification models (such as CNN and ResNet) with text-based classification models (e.g., ClinicalBERT). This hybrid approach leveraged both visual and textual information to improve classification accuracy.
The strategy involved extracting text through Optical Character Recognition (OCR) identifying keywords or phrases, and combining the classification probabilities from both image and text models via a sliding window technique. While this approach improved accuracy, it failed to handle spatial relationships between text elements, which proved critical for correctly classifying documents with complex layouts, such as forms and invoices.
The final document classification solution utilizes a State-of-the-Art (SOTA) image classification model, optimized for document understanding. This model excels by integrating both visual and spatial information, making it highly effective for documents with structured layouts like forms and invoices. Unlike traditional text-based models, which struggle with complex document structures, this SOTA model processes both the visual appearance and spatial arrangement of elements within the document to classify it accurately.How
Dexit’s AI Classifies Documents:
When trained on just 30,000 images from 100 unique document types that were of varying layouts, our final solution was able to provide an overall accuracy of 97% in classification. There were certain document types that had a lot of variations compared to the rest and we were able to observe that the accuracy of such documents was around 85%. This can certainly be improved with more training documents specifically for such document types with high variation in layout.
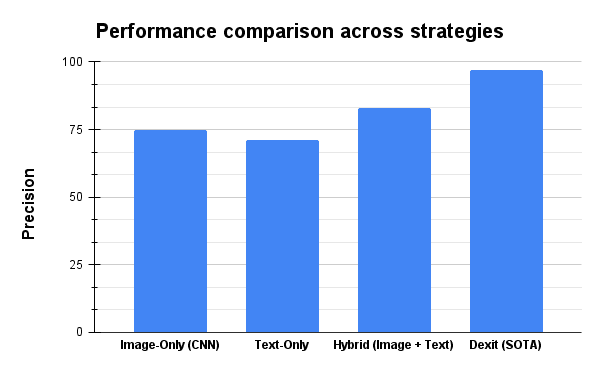
Performance comparison of different document classification models and fusion strategies
For entity extraction, we explored several initial approaches before arriving at a fine-tuned model. These included DocQuery, InternVL 2.0, and BERT for question answering. After extensive evaluation, we discarded these methods due to several critical limitations, as outlined below:
DocQuery, a library designed for analyzing semi-structured and unstructured documents, initially showed promise for extracting entities. However, we faced two significant challenges:
InternVL 2.0, a multimodal model designed to handle long texts, images, and videos, demonstrated competitive performance across a range of tasks. However, it wasn’t suitable for entity extraction due to the following reasons:
While BERT is a powerful model for question answering, applying it directly to entity extraction came with its own set of challenges:
While DocQuery, InternVL 2.0, and BERT for question answering each offer potential for entity extraction, they present limitations that hinder their effectiveness compared to a fine-tuned model. DocQuery's lack of maintenance, InternVL 2.0 focus on question answering, and BERT's need for extensive pre-processing make them less desirable options.
In contrast, our fine-tuned model’s token-level annotations, and optimization through fine-tuning make it a more accurate, efficient, and robust solution for entity extraction in Dexit.
Dexit’s AI employs two distinct methods for entity extraction:
The fine-tuned model is specifically designed for documents undergoing auto-indexing. This approach integrates both OCR and spatial information to ensure high accuracy in entity extraction. The process includes several key stages:
1. Training Data Preparation: For training the model, we make use of the following inputs:
a. The full image as it is.
b. The OCR text from the image:
The document images are processed with a State-of-the-Art OCR engine to extract text. As part of the OCR process, token-level bounding boxes are generated for individual words or characters, capturing fine-grained spatial information about each token.
c. The key:value pairs of the entities that are present in the image.
The key:value pairs along with the OCR text are compiled into a JSON-format labeled
dataset by following some post-processing techniques. This dataset serves as the
foundation for fine-tuning the model, allowing it to learn both the textual context and
spatial relationships of the entities within the document.
2. Fine-tuning: The data is split into train/val/test datasets following a 70/10/20 split. The model is fine-tuned on the train dataset and is also validated on the val dataset in parallel.
3. Inference and Validation: During inference, the image is input into the system where OCR is applied, generating token-level boxes. The model predicts entity labels for each box, which are then compared against a test dataset to validate performance. Ideally, all boxes within a multi-word entity should be correctly identified. This precision is crucial for tasks like auto-indexing, where accuracy directly impacts downstream processing.
Dexit’s AI also uses an alternative method for documents that don't require indexing but might be queried using natural language. This method comprises the following steps:
Here’s Dexit’s way of handling document classification and entity extraction in action:

Building Dexit’s automated document processing wasn’t just about choosing the right models—it was about refining strategies, optimizing performance, and balancing accuracy with real-world constraints. With a fusion of state-of-the-art classification, entity extraction, and auto-indexing, Dexit provides a scalable, high-precision solution for handling complex healthcare document workflows.
And this is just the beginning. As we continue to iterate and improve, we push the limits of AI in document understanding—making automation smarter, faster, and more adaptable with every step.
CONTRIBUTORS BEHIND THE BUILD
Join over 3,200 subscribers and keep up-to-date with the latest innovations & best practices in Healthcare IT.
So, you've deployed your shiny new ML model. It's acing predictions, and life is good. But how do you …

AI models, especially Large Language Models (LLMs), don’t degrade like perishable goods. But over time, you’ll …

Healthcare data is as vast as it is complex, encompassing millions of medical records, clinical notes, …